 Direto Notícias Imparcial, Transparente e Direto!
Direto Notícias Imparcial, Transparente e Direto!



Artigos Relacionados



Esta publicação é de autoria de Anton Aleksandrov, arquiteto principal de soluções da AWS Serverless e Daniel Abib, arquiteto sênior de soluções especializado da AWS.
Os desenvolvedores de aplicativos Serverless geralmente se deparam com cenários em que precisam transportar grandes cargas úteis (payloads), especialmente ao criar aplicativos de nuvem modernos que precisam de dados enriquecidos. Os exemplos incluem serviços de análise com relatórios detalhados, plataformas de comércio eletrônico com extensos catálogos de produtos, aplicativos de saúde que transmitem registros de pacientes ou serviços financeiros que agregam dados transacionais.
Muitos serviços Serverless têm um tamanho máximo de carga útil bem definido. Por exemplo, o tamanho máximo da carga útil de solicitação/resposta do AWS Lambda é 6 MB, e o tamanho máximo de mensagens do Amazon Simple Queue Service (Amazon SQS) e do Amazon EventBridge é 256 KB. Neste artigo, você aprenderá a usar técnicas de compressão de dados para reduzir o espaço ocupado pela rede para transportar cargas úteis maiores sob as restrições atualmente existentes.
Visão geral
Os aplicativos em nuvem evoluem continuamente e precisam ser ajustados com frequência para novos requisitos, como novos recursos de negócios ou novos objetivos de nível de serviço (SLO) para maior taxa de transferência e menor latência. À medida que novos casos de uso e padrões de dados são adicionados, é comum ver o tamanho da carga útil de solicitações e respostas aumentarem. Em algum momento, você pode atingir os limites máximos de tamanho da carga útil do serviço, como 6 MB para invocações síncronas de funções do Lambda, 10 MB para o Amazon API Gateway e 256 KB para invocações do Amazon SQS, EventBridge e Lambda assíncronas.
Há várias técnicas que você pode aplicar ao lidar com grandes cargas úteis. Se suas cargas forem de dezenas de MBs ou mais, ou se você precisar transportar objetos binários grandes com o API Gateway, você pode armazenar a carga no Amazon Simple Storage Service (Amazon S3) e usar URLs pré-assinadas para que os clientes façam upload e download diretamente do S3.

Figura 1. Um exemplo de arquitetura para lidar com grandes cargas
O streaming de respostas de URLs da função Lambda suporta respostas de até 20 MB. Para lidar com mensagens grandes com serviços como SQS ou EventBridge, você pode armazenar a mensagem no S3 e passar uma referência. O consumidor downstream usará a referência para baixar a mensagem diretamente do S3. Uma característica comum dessas técnicas é que elas introduzem complexidade de arquitetura de software e podem exigir modificações na arquitetura da solução e nos padrões de fluxo de dados existentes.
Além disso, à medida que suas cargas aumentam de tamanho, você verá um aumento nos custos de transferência de dados, especialmente se sua solução estiver transportando dados por meio de gateways NAT da Amazon Virtual Private Cloud (VPC), endpoints de VPC ou enviando dados entre regiões da AWS. Por exemplo, é comum que soluções baseadas em VPC tenham funções Lambda em sua arquitetura. Um container que é executado no Amazon Elastic Kubernetes Service (Amazon EKS) pode precisar invocar uma função Lambda, ou uma função Lambda conectada à VPC pode precisar acessar a Internet pública.

Figura 2. Exemplos de uso de dispositivos de rede virtual (ENI) com aplicativos Serverless
Tanto o NAT Gateway quanto o VPC Endpoint são cobrados por GB de dados processados, o que torna a compactação de dados uma técnica de otimização valiosa. Consulte os preços do
NAT Gateway e os preços do
VPC Endpoint para obter detalhes.
As seções a seguir exploram as técnicas de compactação de dados e demonstram como aplicá-las em seus aplicativos Serverless. Você pode aprender a enviar cargas maiores dentro dos limites de tamanho de carga existentes e reduzir o espaço ocupado pela rede sem alterações de arquiteturas significativas. Esta postagem discute técnicas de compressão no contexto do Lambda e do API Gateway, mas os mesmos princípios podem ser aplicados a outros serviços, como SQS, EventBridge e AWS AppSync. O entendimento dos conceitos de compressão permite que você otimize melhor os recursos de tratamento de dados do seu aplicativo.
O que é compactação de dados?
A compactação é uma abordagem amplamente usada para reduzir o tamanho dos dados a fim de melhorar a relação custo-benefício e o desempenho do armazenamento e transmissão de dados. Muitas ferramentas e estruturas incorporam técnicas de compressão de dados, como gzip ou zstd. Estão completamente documentado na especificação oficial da IANA e na RFC 9110 da IETF. Navegadores como Chrome e Firefox, kits de ferramentas HTTP como curl e Postman e runtimes como Node.js e Python lidam com compactação de forma nativa, geralmente sem o envolvimento do usuário.
Considere o protocolo HTTP. Quando um cliente deseja enviar uma carga comprimida, ele a especifica no cabeçalho Content-Type. Para receber uma resposta compactada, o cliente especifica os métodos de compactação compatíveis no cabeçalho da solicitação Accept-Encoding.

Figura 3. Cabeçalho da solicitação Accept-Encoding especificando os métodos de compactação suportados
O servidor comprime a carga de resposta usando um dos métodos suportados e usa o cabeçalho de resposta Content-Encoding para indicar o método ao cliente.

Figura 4. Cabeçalho de resposta de codificação de conteúdo especificando o método de compactação
Esse mecanismo pode acelerar as comunicações cliente-servidor reduzindo o número de bytes transmitidos pela rede. A eficiência da compressão depende do tipo de dados. Formatos baseados em texto, como JSON, XML, HTML e YAML, são bem compactados, enquanto dados binários, como PDF e JPEG, geralmente são compactados com menos eficiência.
Compressão de dados com API Gateway
O API Gateway fornece suporte de compressão integrado. Use a configuração MinimumCompressionSize para definir o menor tamanho de carga útil para compactar automaticamente. O valor pode estar entre 0 bytes e 10 MB. Comprimir cargas muito pequenas pode, na verdade, aumentar o tamanho final da carga útil, e você deve sempre testar seus padrões reais de carga útil para determinar o limite ideal.

Figura 5. Como lidar com a compactação de dados no API Gateway
O API Gateway permite que os clientes interajam com sua API usando cargas comprimidas por meio de codificações de conteúdo compatíveis. O mecanismo de compressão funciona bidirecionalmente. Para cargas JSON, o API Gateway lida perfeitamente com a compactação e a descompactação, mantendo a compatibilidade com modelos de mapeamento. Ele descompacta as cargas de entrada antes de aplicar os modelos de mapeamento de solicitações e compacta as respostas de saída após aplicar os modelos de mapeamento de respostas. Essa compactação automatizada otimiza a transferência de dados:
- Ao enviar dados compactados, os clientes fornecem o cabeçalho Content-Encoding apropriado. O API Gateway manipula a descompressão e aplica modelos de mapeamento configurados antes de encaminhar a solicitação para a integração.
- Quando o API Gateway recebe uma resposta de integração e a compactação é ativada, ele compacta a carga útil da resposta e a retorna ao cliente, desde que o cliente tenha incluído um cabeçalho Accept-Encoding correspondente.
Um exemplo usando a técnica de compressão com o API Gateway e a carga JSON gerou os seguintes resultados.
- Compressão desativada. Tamanho da resposta = 1 MB, latência de resposta = 660 ms
- Compressão ativada. Tamanho da resposta = 220 KB, latência de resposta = 550 ms
A compactação de dados resultou em 78% de redução do espaço ocupado pela rede e aumento da latência em 110 ms.
Essa técnica baseada em configuração usa a compactação nativa do API Gateway. No entanto, as cargas são descompactadas antes de serem entregues às integrações downstream, portanto, elas ainda permanecem sujeitas ao tamanho máximo de carga útil de 6 MB do Lambda. Para resolver isso, você pode configurar BinaryMediaTypes no API Gateway para transmitir cargas comprimidas diretamente para o Lambda, permitindo que a função manipule a descompressão.
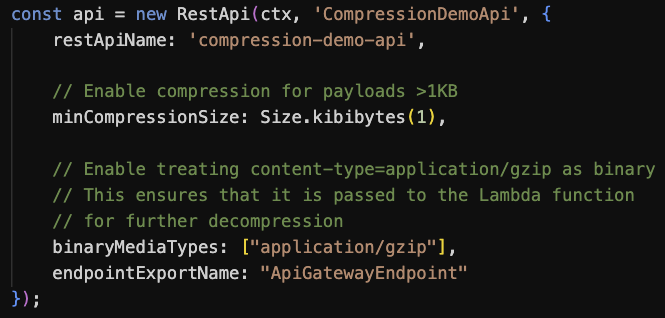
Figura 6. Código CDK para configurar o API Gateway para compressão de dados e passagem de dados binários
Manipulação de dados compactados em funções do Lambda
A API Lambda Invoke oferece suporte a cargas em formatos de texto sem formatação, como JSON. O tamanho máximo da carga útil é de 6 MB para invocações síncronas e 256 KB para assíncronas. Embora a API Invoke ofereça suporte a cargas úteis baseadas em texto não compactado, você pode introduzir a compactação de dados em seu código de função e usar o API Gateway ou os URLs de função para facilitar a conversão de conteúdo, conforme ilustrado na figura a seguir.

Figura 7. Transportando cargas comprimidas em aplicativos Serverless
O tratamento da compactação de dados em seu código de função do Lambda pode ser feito por meio de bibliotecas comumente incorporadas ao tempo de execução. O trecho de código a seguir mostra a carga útil da resposta de compactação usando o Node.js. Técnicas similares podem ser aplicadas a outros tempos de execução.
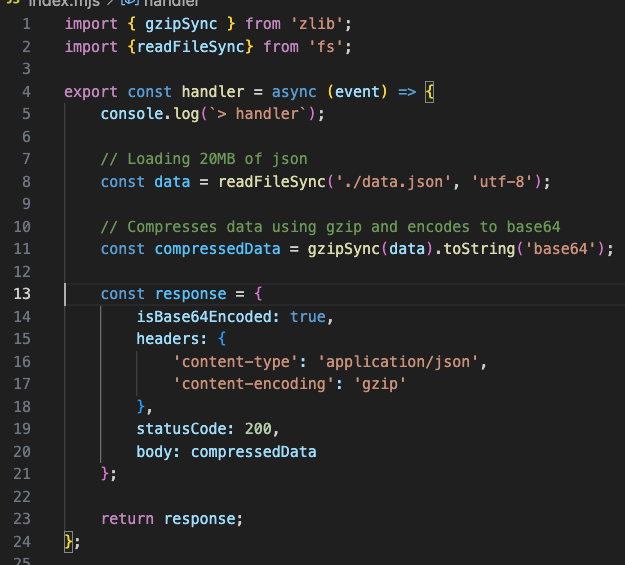
Figura 8. Código de exemplo implementando compressão de carga útil de resposta em uma função Lambda
- Linha 1: Importe a funcionalidade gzip do módulo zlib.
- Linhas 11: Comprimir e codificar dados em Base64. A compactação Gzip, semelhante a muitos outros métodos de compactação, produz um fluxo binário. A codificação Base64 o converte para o formato baseado em texto esperado pelo serviço Lambda
- Linhas 13-21: O objeto de resposta é criado com isBase64encoded=true e cabeçalhos de resposta informando ao cliente que a resposta é um objeto JSON codificado em gzip.
A captura de tela a seguir mostra o resultado: 20 MB de JSON não compactado retornado de uma função Lambda como um corpo de resposta compactado de 2,5 MB. O espaço ocupado pela rede foi reduzido em mais de 80%.

Figura 9. Uma captura de tela do Postman mostrando o tamanho da carga útil original e compactada
Usando essa técnica, você pode reduzir o espaço ocupado pela rede e transportar os tamanhos de carga útil várias vezes acima do tamanho máximo da carga útil do Lambda.
Usando URLs de função com cargas compactadas
O transporte de cargas compactadas por meio de URLs de funções Lambda não exige nenhuma configuração extra. Para respostas do manipulador (handler), seu código precisa compactar e codificar os dados em Base64, conforme mostrado na figura anterior. Para solicitações de invocação, o endpoint do URL da função reconhece a carga comprimida recebida como binária e a passa para o manipulador como uma string codificada em Base64 no corpo do evento.

Figura 10. Exemplo implementando a descompactação da carga útil da solicitação em uma função Lambda
Compactação e resultados de testes
A compactação de dados no código da função é uma atividade que consome muita CPU, aumentando potencialmente a duração da invocação e, consequentemente, o custo da função. Isso, no entanto, pode ser equilibrado pelos benefícios da compactação de dados. Como você viu nas seções anteriores, embora a compactação de dados aumente a latência computacional, o transporte de cargas menores pela rede reduz a latência da rede. A seção a seguir resume uma série de testes realizados para estimar o impacto da compactação de dados na duração da invocação da função Lambda, no custo da invocação da função Lambda e na economia de transferência de dados com o NAT Gateway e o VPC Endpoint. Os testes foram realizados com várias suposições e dados JSON gerados aleatoriamente. Você pode ver os resultados completos dos testes no repositório de amostra do GitHub.com.
Os resultados dos testes demonstraram que o impacto na latência e no custo da função depende principalmente de dois fatores principais: tamanho da carga útil e memória alocada (que determina a capacidade da vCPU). Usando um runtime Node.js com arquitetura ARM como exemplo, compactar um objeto JSON de 1 MB em uma função com 1 GB de memória alocada resultou em 124 ms de tempo de processamento adicional, em média. Para 10 milhões de invocações, esse tempo extra de processamento adiciona aproximadamente $16 USD. Ao mesmo tempo, a compressão resultou em uma redução de 70% no tamanho da carga útil. Com o mesmo número de invocações, isso se traduz em aproximadamente $300 USD em economia ao usar o NAT Gateway e $70 USD em economia ao usar VPC Endpoints (dependendo do número de zonas de disponibilidade (AZs)).
Os preços dos serviços da AWS são atualizados regularmente. Você deve sempre consultar as respectivas páginas de preços para obter as informações mais recentes. Além disso, você deve realizar suas próprias estimativas de desempenho e custo usando cargas que representem suas cargas de trabalho. A eficácia da compactação varia significativamente dependendo do tipo de dados: cargas com baixas taxas de compactação podem não se beneficiar dessa técnica.
Aplicação de exemplo
Siga as instruções neste repositório do GitHub para provisionar um exemplo de aplicação na sua conta da AWS. O projeto cria duas funções Lambda para demonstrar o recebimento e o retorno de JSON compactado usando URLs de funções e API Gateway.
O exemplo mostra como obter (GET) e publicar (POST) cargas JSON usando a compressão gzip para reduzir o espaço ocupado pela rede em mais de 80%.

Figura 11. Uma captura de tela do Postman mostrando o tamanho da carga útil original e compactada
Conclusão
A compactação de dados permite maiores transferências de carga útil e reduz o espaço utilizado pela rede. Isso pode ajudar a reduzir as latências da rede e otimizar os custos de transferência de dados. Ao implementar a compactação nas funções do Lambda, é importante considerar sua natureza vinculada à CPU, o que pode aumentar a duração e os custos da função. Você deve sempre avaliar o custo adicional de computação em relação às possíveis economias na transferência de dados para garantir que a técnica beneficie seu caso de uso.
A compactação é mais eficaz para lidar com grandes cargas úteis baseadas em texto e introduz um pequeno aumento na latência computacional equilibrado pela redução da latência da rede é aceitável.
Para saber mais sobre arquiteturas Serverless e padrões de invocação assíncrona do Lambda, consulte Serverless Land.
Este blog post foi traduzido e o conteúdo original está neste link.
Autores
Tradutor
 |
Daniel Abib é Arquiteto de Soluções Sênior e Especialista em Amazon Bedrock na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e especialização em Machine Learning. Ele trabalha apoiando Startups, ajudando-os em sua jornada para a nuvem. |
Revisor
 |
Rodrigo Peres é arquiteto de soluções na AWS, com mais de 20 anos de experiência trabalhando com arquitetura de soluções, desenvolvimento de sistemas e modernização de sistemas legados. |
